Spring
Spring
# 1 Spring常见问题
# 1.1 BeanFactory与FactoryBean的区别?
1.BeanFactory:IOC容器的核心接口,负责生产和管理Spring中的Bean。
ApplicationContext就是BeanFactory的一种,继承了BeanFactory的功能,又扩展了很多其他功能。
2.FactoryBean:也是一个接口,通过实现FactoryBean接口,可以创建一个我们自己定义的Bean,这个Bean只会经过Spring的Bean生命周期步骤中的初始化后,其他生命周期步骤不会经过。Spring整合Mybatis的时候,就是通过FactoryBean的方式,将Mybatis中的sql对应的接口转化成Spring的Bean对象。

# 1.2 BeanFactory与ApplicationContext的区别?
ApplicationContext由BeanFactory派生而来,拥有比BeanFactory更多的功能,比如:
1.支持国际化功能。
2.支持事件机制(发布订阅)。
3.支持底层资源访问,可以用来加载多个Resource。
4.支持web应用。
# 1.3 Spring整合Mybatis后为什么会导致一级缓存失效?
Mybatis的一级缓存是利用SqlSession实现的,同样的sql,如果在同一个SqlSession执行,就会利用一级缓存,提高查询效率。
Spring整合Mybatis后,执行方法时,如果方法没有加@Transactional注解,那么方法里面执行sql时,每个sql要执行时都会先生成一个新的SqlSession去执行该sql,所以一级缓存会失效。如果加上@Transactional注解,即开启事务,则同个方法内多个sql使用的是同一个SqlSession,从而一级缓存能生效。
# 2 Bean的生成过程
# 2.1 生成BeanDefinition
Spring启动的时候会进行扫描,扫描指定包路径下的所有.class文件,并得到BeanDefinition的Set集合。(Spring源码中将class文件包装成Resource对象,遍历每个Resource对象。解析.class文件利用的是ASM技术,并没有加载这个类到JVM。)
什么是BeanDefinition?
Bean定义,存在很多属性来描述一个Bean的特点。比如:
class:表示bean类型。
scope:表示bean的作用域,如单例、原型等。
lazyInit:表示类是否懒加载。
initMethodName:表示Bean初始化时要执行的方法。
destroyMethodName:表示Bean销毁时要执行的方法。
# 2.2 合并BeanDefinition
Spring中支持父子BeanDefinition,child会继承parent上定义的属性。
# 2.3 加载类
加载BeanDefinition所对应的class。
# 2.4 实例化前(扩展点)
BeanDefinition对应的类成功加载后,就可以实例化对象了。但是在Spring中,实例化对象之前,Spring提供了一个扩展点:InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation()

如果按上面例子,在实例化前直接返回一个自己定义的对象,则表示不需要Spring来实例化了,并且后面的Spring依赖注入也不会进行,会跳过一些步骤,直接执行到 初始化后 这一步。
# 2.5 实例化
根据BeanDefinition去创建一个对象。
1.BeanDefinition中是否设置了Supplier,如果设置了则调用Supplier的get()得到对象。
2.BeanDefinition中是否设置了factoryMethod,如果设置了则调用工厂方法得到对象。
3.创建对象前,推断构造方法。
# 2.6 BeanDefinition的后置处理(扩展点)
Bean对象实例化出来之后,接下来可以给对象属性赋值了。但是在赋值之前,Spring又提供了一个扩展点可以对此时的BeanDefinition进行加工:
MergedBeanDefinitionPostProcessor.postProcessMergedBeanDefinition()

# 2.7 实例化后(扩展点)
处理完BeanDefinition,Spring还提供一个扩展点处理实例对象:
InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation()

# 2.8 处理属性
处理@Autowired、@Resource、@Value等注解,通过以下扩展点实现:
InstantiatiionAwareBeanPostProcessor.postProcessProperties()
我们甚至可以以此实现一个自己的注入功能,如:

# 2.9 执行Aware(扩展点)
完成属性赋值后,Spring会执行一些回调,包括:
1.BeanNameAware:回传beanName给bean对象。
2.BeanClassLoaderAware:回传classLoader给bean对象。
3.BeanFactoryAware:回传beanFactory给对象。
# 2.10 初始化前(扩展点)
Spring提供的一个扩展点:
BeanPostProcessor.postProcessBeforeInitialization()

在Spring源码中:
1.InitDestroyAnnotationBeanPostProcessor会在初始化前这个步骤中执行**@PostConstruct**的方法。
2.ApplicationContextAwareProcessor会在初始化前这个步骤进行其他Aware的回调:
1)EnvironmentAware:回传环境变量
2)EmbeddedValueResolverAware:回传占位符解析器
3)ResourceLoaderAware:回传资源加载器
4)ApplicationEventPublisherAware:回传事件发布器
5)MessageSourceAware:回传国际化资源
6)ApplicationStartupAware:回传应用其他监听对象,可忽略
7)ApplicationContextAware:回传Spring容器ApplicationContext
# 2.11 初始化
1.当前Bean对象是否实现了InitializingBean接口,实现了就调用其**afterPropertiesSet()**方法。
2.执行BeanDefinition中指定的初始化方法。

# 2.12 初始化后(扩展点)
Bean创建生命周期中的最后一个步骤,Spring提供的一个扩展点:
BeanPostProcessor.postProcessAfterInitialization()

可以在这个步骤中对Bean进行最终处理。
Spring中的AOP就是基于初始化后实现的。初始化后返回的对象才是最终的Bean对象。
# 3 Bean的销毁过程
Bean销毁是发生在Spring容器关闭过程中的。
1.在Bean创建过程中,最后(初始化后)有一个步骤去判断当前创建的Bean是不是DisposableBean:
1)当前Bean是否实现了DisposableBean接口。
2)当前Bean是否实现了AutoCloseable接口。
3)BeanDefinition中是否指定了destroyMethod。
4)调用DestructionAwareBeanPostProcessor.requiresDestruction(bean)进行判断。
5)把符合上述任意一个条件的Bean适配成DisposableBeanAdapter对象,并存入disposableBeans中。其中disposableBeans是一个LinkedHashMap。
2.在Spring容器关闭过程时:
1)首先发布ContextClosedEvent事件。
2)调用lifecycleProcessor的onCloese()方法。
3)遍历disposableBeans销毁单例Bean。
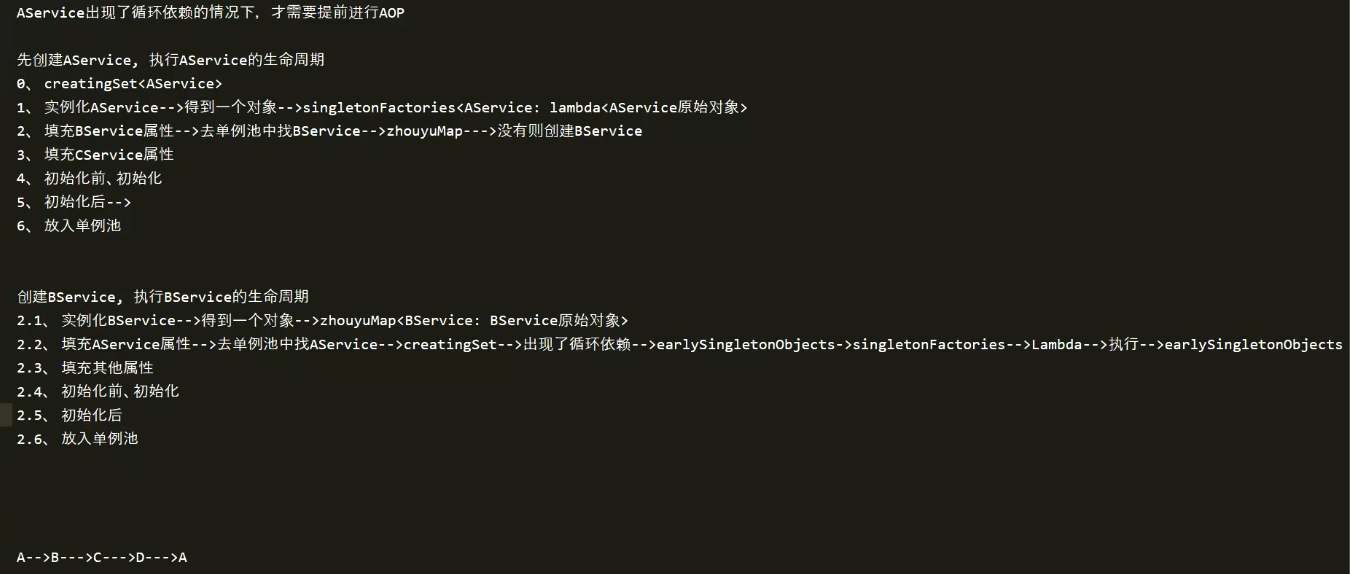
# 4 什么是循环依赖?
A创建时 --> 需要B --> B去创建时 --> 需要A,从而产生循环。
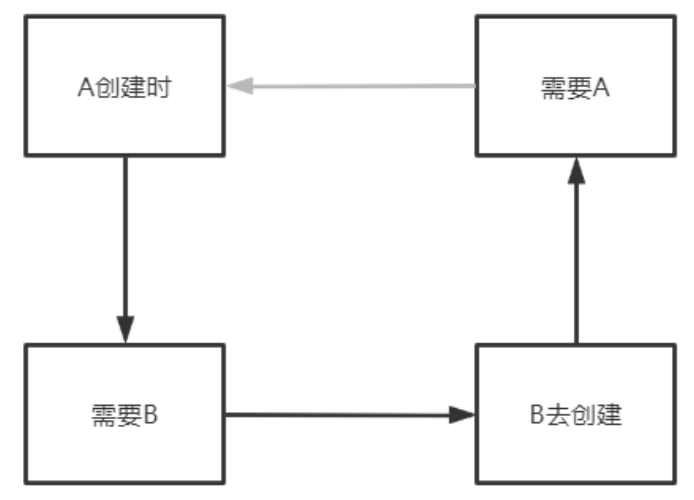
如何打破循环,加个中间人(缓存)
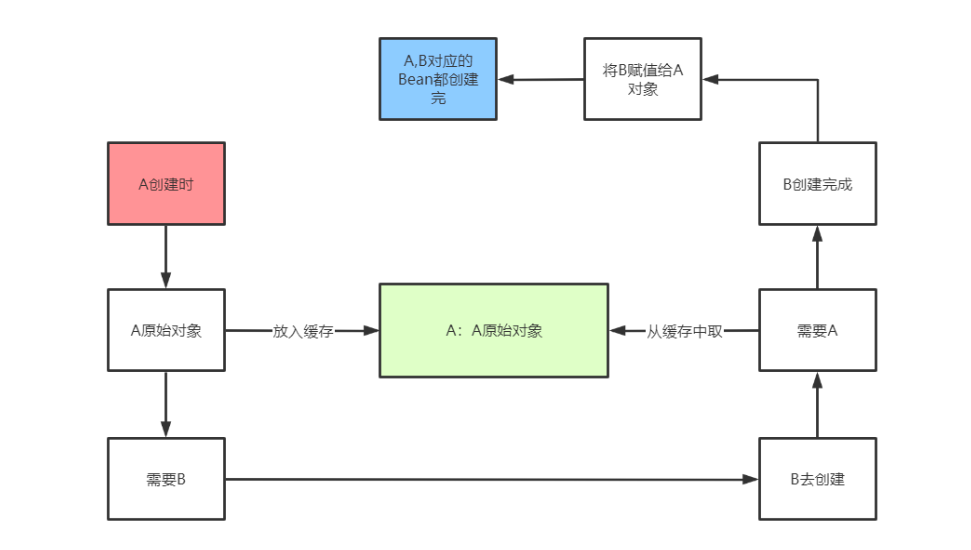
实际上就是使用了三级缓存解决循环依赖。
# 5 详细讲下三级缓存?
# 5.1 singletonObjects(一级缓存:单例池)
缓存经过了完整生命周期的bean。
# 5.2 earlySingletonObjects(二级缓存)
缓存未经过完整生命周期的bean,只要某个bean出现了循环依赖,就会提前把这个暂时未经过完整生命周期的bean放入earlySingletonObjects中(这个bean如果要经过AOP,那么就会把代理对象放入earlySingletonObjects中,否则就是把原始对象放入earlySingletonObjects),即使是代理对象,代理对象所代理的原始对象也是没有经过完整生命周期的。
# 5.3 singletonFactories(三级缓存)
缓存的是一个Lambda表达式。在每个Bean的生成过程中,经过实例化得到一个原始对象后,都会提前基于原始对象暴露一个Lambda表达式,并保存到三级缓存中(这个Lambda表达式可能用到也可能用不到,如果当前Bean没有出现循环依赖,那么这个Lambda表达式没用)。如果当前bean在依赖注入时发现出现了循环依赖,则从三级缓存中拿到Lambda表达式,并执行Lambda表达式得到一个对象,并把得到的对象放入二级缓存。
# 5.4 earlyProxyReferences
其实还要一个缓存,就是earlyProxyReferences,它用来记录某个原始对象是否进行过AOP了。
# 6 为什么需要第三级缓存?
主要为了处理AOP的问题。
如果没有第三级缓存earlySingletonObjects,则每个bean在依赖注入之前都要去进行AOP的操作,不符合bean的生命周期步骤设计,即AOP对象是在初始化之后生成。
有第三级缓存,则没有循环依赖的需要AOP对象可以按bean的生命周期步骤进行,有循环依赖的需要AOP对象在依赖注入时通过三级缓存中Lambda表达式获取AOP对象放入二级缓存。初始化后要生成AOP对象时去判断是否已经生成过,已生成则不再处理。