
 分布式
分布式
# 1 RPC的工作过程
RPC(Remote Procedure Call)即远程过程调用,允许一台计算机调用另一台计算机上的程序得到结果,而代码中不需要做额外的编程,就像在本地调用一样。
现在互联网应用的量级越来越大,单台计算机的能力有限,需要借助可扩展的计算机集群来完成,分布式的应用可以借助RPC来完成机器之间的调用。
在RPC框架中主要有三个角色:Provider、Consumer和Registry。如下图所示:
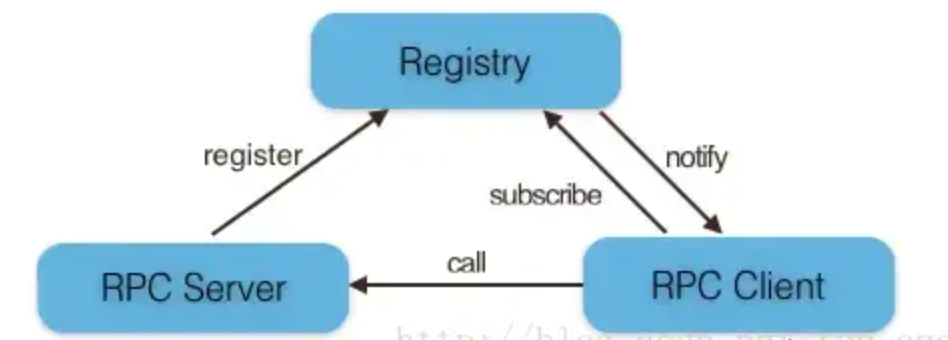
RPC调用流程:
1)服务消费方(client)调用以本地调用方式调用服务;
2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
3)client stub找到服务地址,并将消息发送到服务端;
4)server stub收到消息后进行解码;
5)server stub根据解码结果调用本地的服务;
6)本地服务执行并将结果返回给server stub;
7)server stub将返回结果打包成消息并发送至消费方;
8)client stub接收到消息,并进行解码;
9)服务消费方得到最终结果。
# 2 雪花算法
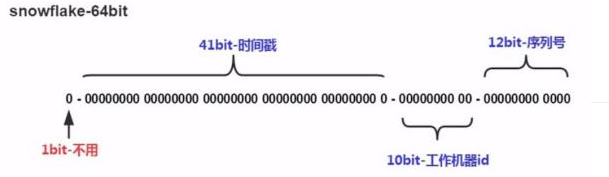
41bit时间戳:这里采用的就是当前系统的具体时间,单位为毫秒。
10bit工作机器ID(workerId):每台机器分配一个id,标示不同的机器,上限1024,标示一个集群某个业务最多部署的机器个数上限。
12bit序列号(自增域):表示在某一毫秒下,这个自增域最大可以分配的bit个数,在当前这种配置下,每一毫秒可以分配2^12个数据,也就是说QPS可以到 409.6 w/s。
存在问题
时间回拨问题:由于机器的时间是动态的调整的,有可能会出现时间跑到之前几毫秒,如果这个时候获取到了这种时间,则会出现数据重复。
机器id分配及回收问题:目前机器id需要每台机器不一样,这样的方式分配需要有方案进行处理,同时也要考虑,如果改机器宕机了,对应的workerId分配后的回收问题。
机器id上限:机器id是固定的bit,那么也就是对应的机器个数是有上限的,在有些业务场景下,需要所有机器共享同一个业务空间,那么10bit表示的1024台机器是不够的。
# 3 什么是跨域?跨域问题怎么解决?
协议、域名、端口号有一个不一样就是跨域。
跨域:跨域访问,简单来说就是A网站的javascript代码试图访问B网站,包括提交内容和获取内容。由于安全原因,跨域访问是被各大浏览器所默认禁止的。
目前我了解的解决跨域的几种方式:
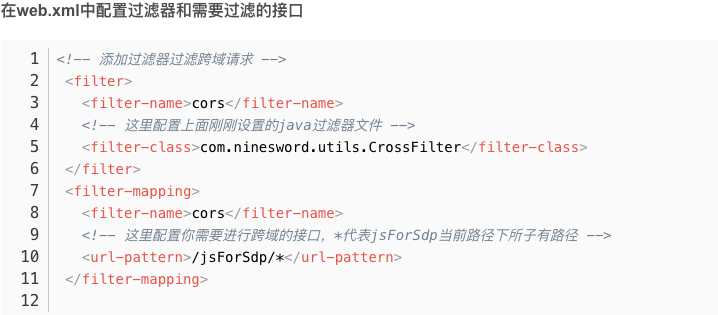
1)手写过滤器
2)手写拦截器
3)jsonp
4)注解方式
5)配置nginx反向代理
共五种解决方式。

# 4 CAP理论,Eureka与Zookeeper区别?
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性Consistency)、A(可用性Availability)和P(分区容错性Partition tolerance)。
由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。
在此Zookeeper保证的是CP, 而Eureka则是AP。
1)当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。
但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。
问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。
2)Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。
而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
# 5 SOA和微服务架构的区别?
SOA (全称:Service Oriented Architecture)
一、架构划分不同
1、SOA强调按水平架构划分为:前、后端、数据库、测试等;
2、微服务强调按垂直架构划分,按业务能力划分,每个服务完成一种特定的功能,服务即产品。
二、技术平台选择不同
1、SOA应用倾向于使用统一的技术平台来解决所有问题;
2、微服务可以针对不同业务特征选择不同技术平台,去中心统一化,发挥各种技术平台的特长。
三、系统间边界处理机制不同
1、SOA架构强调的是异构系统之间的通信和解耦合;(一种粗粒度、松耦合的服务架构);
2、微服务架构强调的是系统按业务边界做细粒度的拆分和部署。
四、主要目标不同
1、SOA架构,主要目标是确保应用能够交互操作;
2、微服务架构,主要目标是实现新功能、并可以快速拓展开发团队。