
 hashMap
hashMap
# 1 数组和链表区别?
1.链表通过指针来连接元素与元素,数组则是把所有元素按次序依次存储。
链表的插入删除元素相对数组较为简单,不需要移动元素,且较为容易实现长度扩充,但是寻找某个元素较为困难。
3.数组寻找某个元素较为简单,但插入与删除比较复杂,由于最大长度需要再编程一开始时指定,故当达到最大长度时,扩充长度不如链表方便。
# 2 HashMap的数据结构?默认初试容量和负载因子是多少?
1.数组+链表+红黑树
初始容量(16)和负载因子(0.75)(负载因子就是指填充到多少开始扩大容量)。
存储数据达到了12时,扩容数组;链表长度到了8,一般要将链表转换为红黑树,如果数组长度没到64,就要优先扩容数组
# 3 hashmap的数组长度为什么要保证是2的幂?
HashMap添加元素时,主要通过 key的hashcode值 & (容器长度 - 1)来进行位置确定。
公式:index = e.hash & (newCap - 1)
length - 1的值是所有二进制位全为1,这种情况下,index的结果等同于hashcode后几位的值。
只要输入的hashcode本身分布均匀,hash算法的结果就是均匀的。
所以,HashMap的默认长度为16,是为了降低hash碰撞的几率。
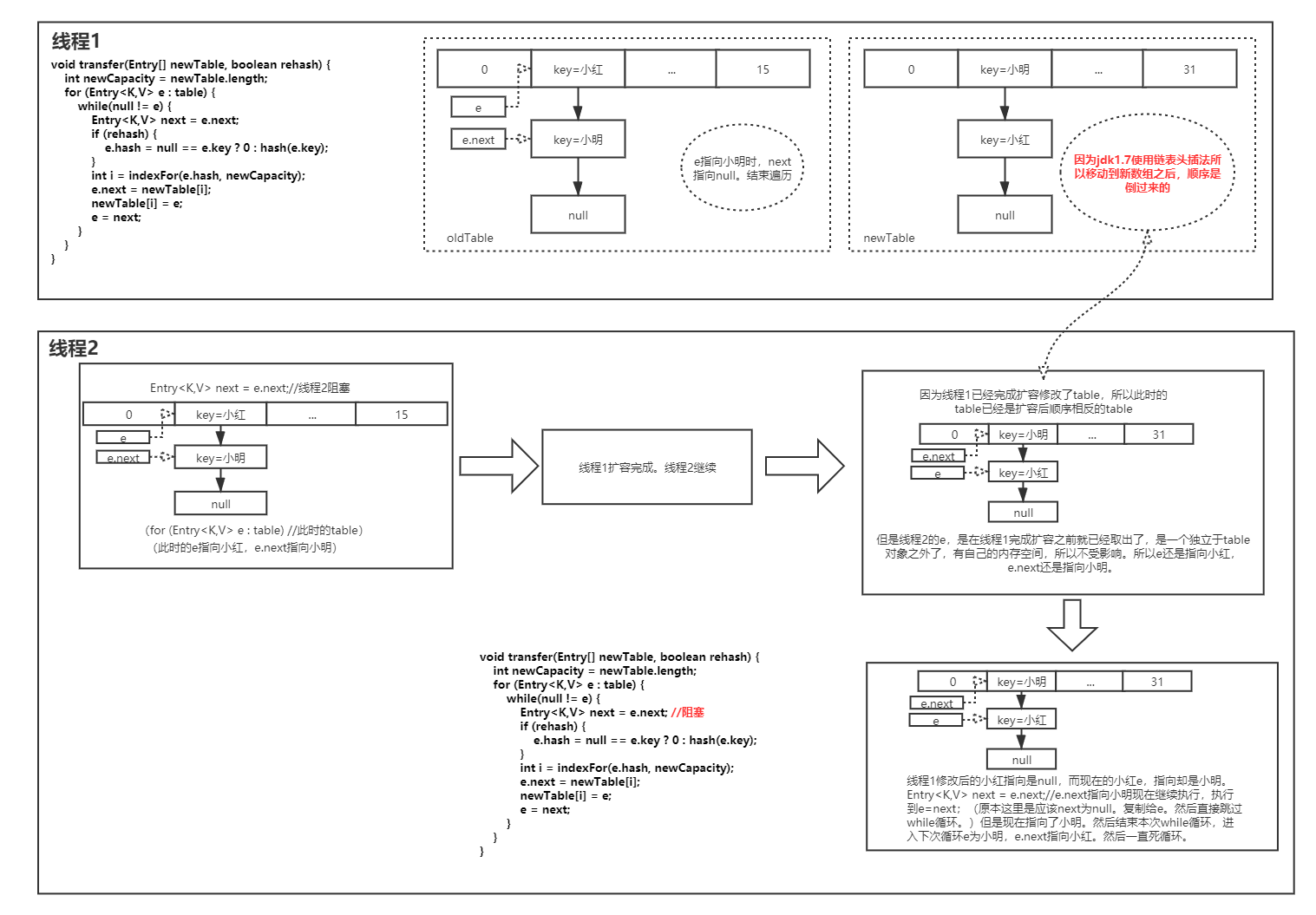
# 4 hashmap的扩容?
rehash:当Map中的元素大于数组长度的75%时,就会进行扩容,JDK1.7之前扩容时很有可能会造成环链,后续get时则可能会变成死循环,线程不安全。
# 5 ConcurrentHashMap
JDK1.7中ConcurrentHashMap采用分段锁,分成16个小的hashMap,锁定当前的小hashMap其他
hashMap不受影响。JDK1.8之后不再采取分段锁,主要采用CAS原子指令实现无锁的高并发操作。
# 6 ConcurrentHashMap 1.7 与 1.8 区别?
1.JDK1.8 采用 synchronized 代替可重入锁 ReentrantLock。
2.JDK1.8 取消了 Segment 分段锁的数据结构,使用数组+链表+红黑树的结构代替。
3.JDK1.8 对每个数组元素加锁,1.7 对要操作的 Segment 数据段加锁。