
 CPU缓存一致性协议MESI
CPU缓存一致性协议MESI
# CPU高速缓存(Cache Memory)
MESI协议动态演示视图 (opens new window)
# CPU为何要有高速缓存?
为了解决内存和硬盘I\O性能跟不上CPU高速运算需要的数据,CPU厂商在CPU中内置了少量的高速缓存以解决I\O速度和CPU运算速度之间的不匹配问题,发挥最大CPU效率
# 时间局部性(Temporal Locality)
如果一个信息项目正在被访问,那么近期它很可能还会被再次访问;例如:循环、递归、方法的反复调用
# 空间局部性(Spatial Locality):
如果一个存储器的位置被引用,那么将来它附近的位置也会被引用;例如:顺序执行的代码、连续创建的两个对象、数组等
# 带有高速缓存的CPU执行计算的流程
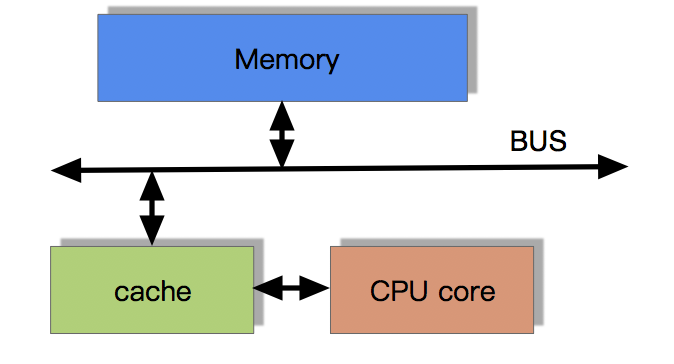
- 1、程序以及数据被加载到主内存(Memory)
- 2、指令和数据被加载到CPU的高速缓存(cache)
- 3、CPU执行指令,把结果写到高速缓存(cache)
- 4、高速缓存中的数据写回主内存(Memory)
# 目前流行的多级缓存结构
由于CPU的运算速度超越了1级缓存的数据I\O能力,CPU厂商又引入了多级的缓存结构
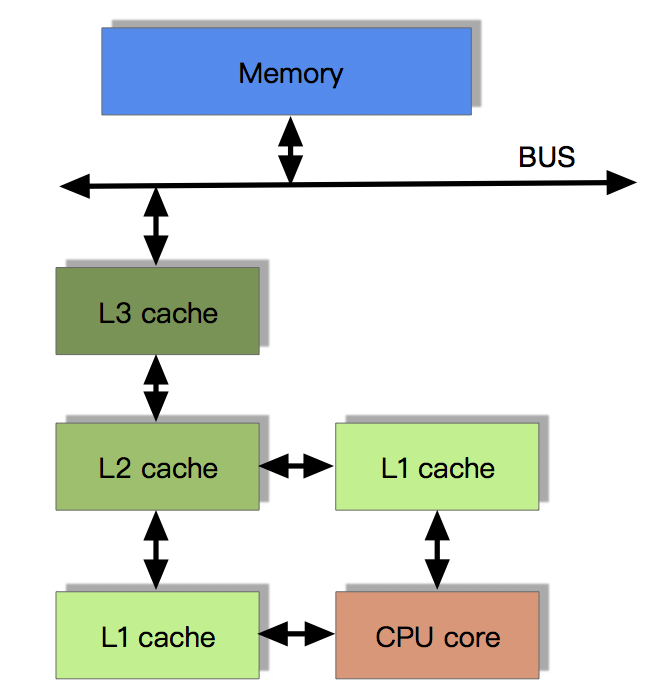
# 多核CPU多级缓存一致性协议MESI
# MESI协议缓存状态
MESI 是指4中状态的首字母。每个Cache line有4个状态,可用2个bit表示
# 缓存行(Cache line)
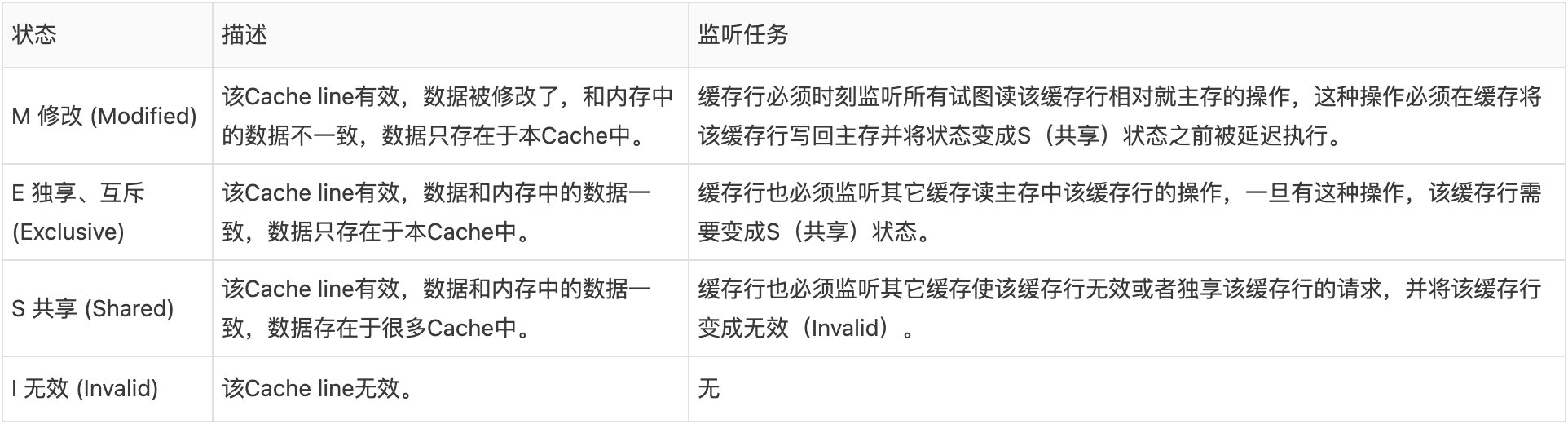
注意
⚠️
# 对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的
# 1、如果一个缓存处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了改缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其他缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
# 2、从上面的意义看来E状态是一种投机性的优化:如果一个CPU想修改一个处于S状态的缓存行,总线事务需要将所有该缓存行的copy变成invalid状态,而修改E状态的缓存不需要使用总线事务
# MESI状态转换
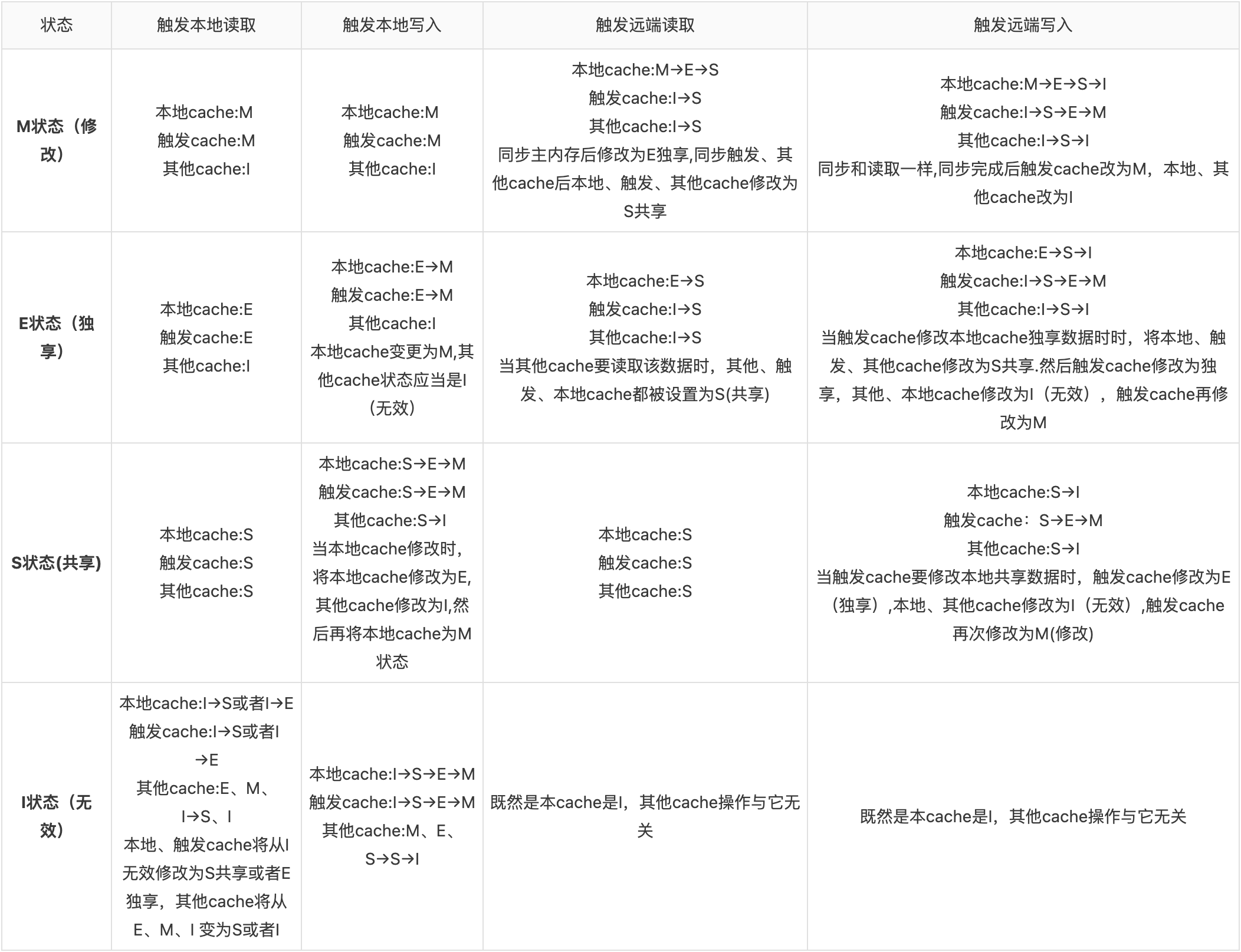
# 多核缓存协同操作
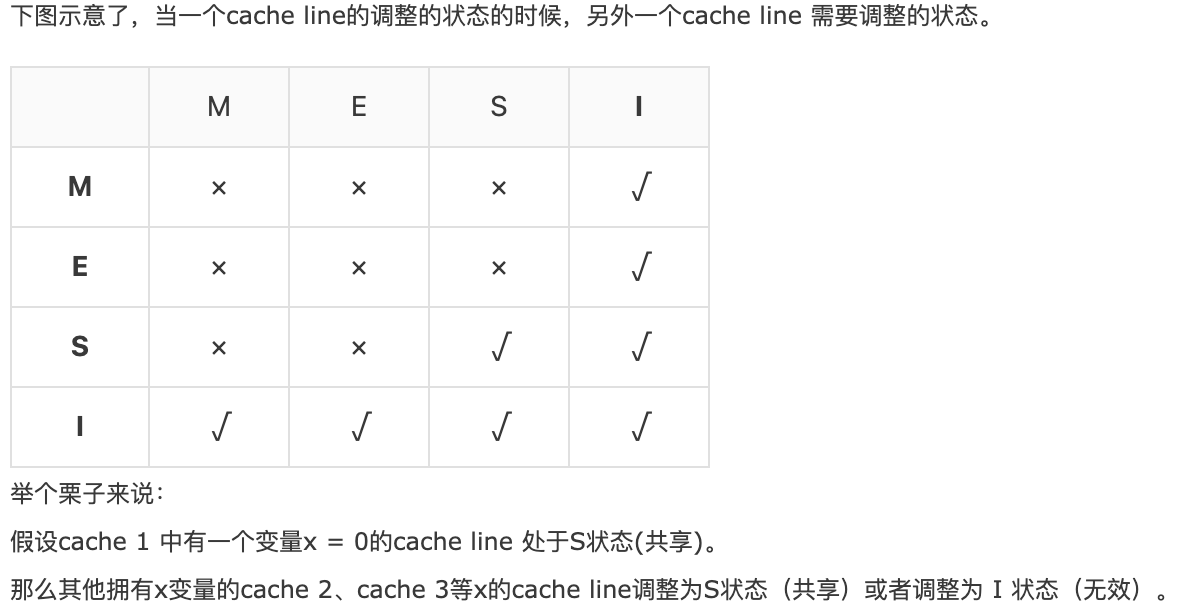
# 单核读取
CPU A发出了一条指令,从主内存中读取x。从主内存通过bus读取到缓存中(远端读取Remote read),这时该Cache line修改为E状态(独享)
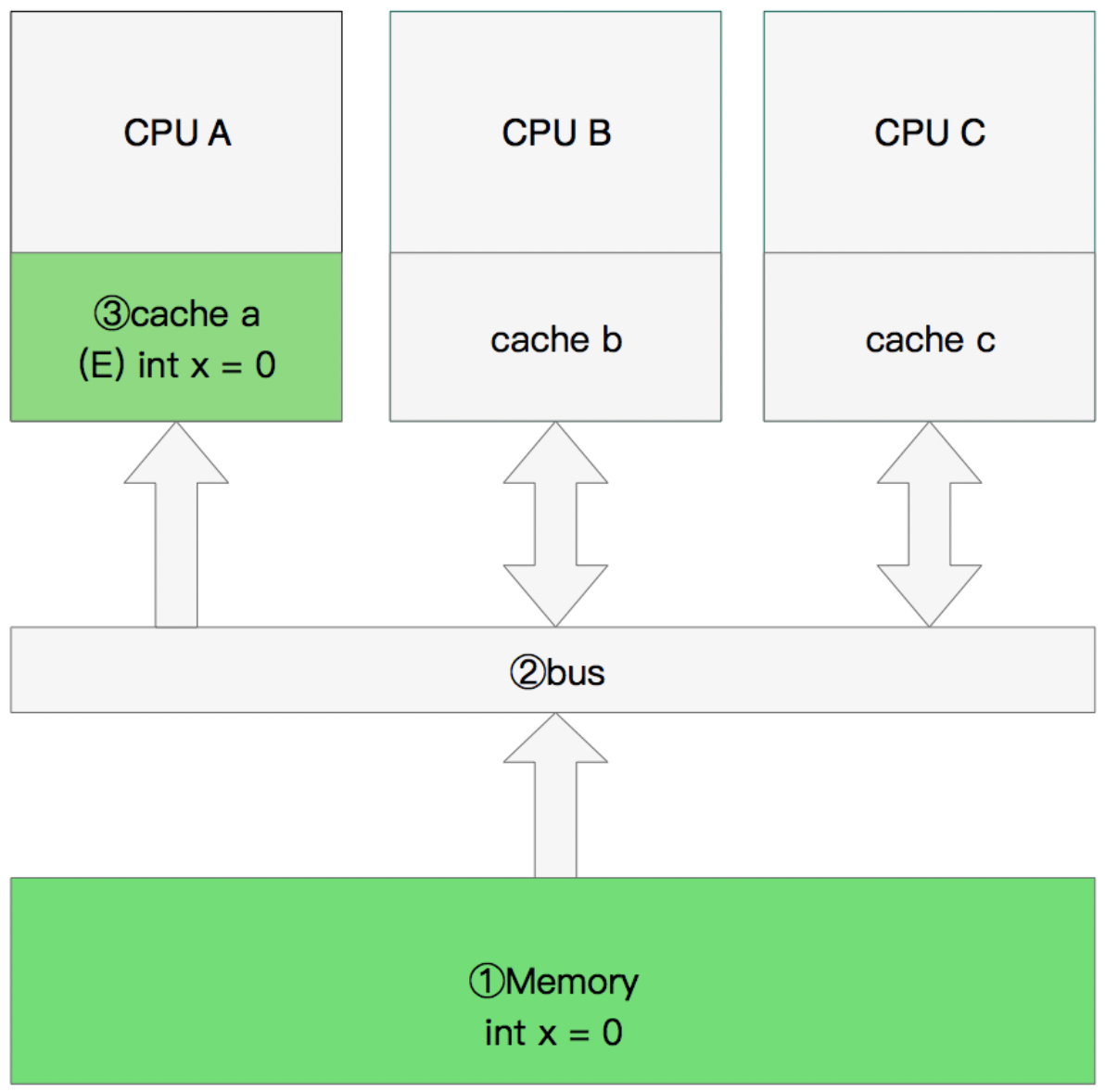
# 两核读取
- CPU A发出了一条指令,从主内存中读取x
- CPU A从主内存通过bus读取到 cache a中并将该cache line 设置为E状态。
- CPU B发出了一条指令,从主内存中读取x。
- CPU B试图从主内存中读取x时,CPU A检测到了地址冲突。这时CPU A对相关数据做出响应。此时x 存储于cache a和cache b中,x在chche a和cache b中都被设置为S状态(共享)。
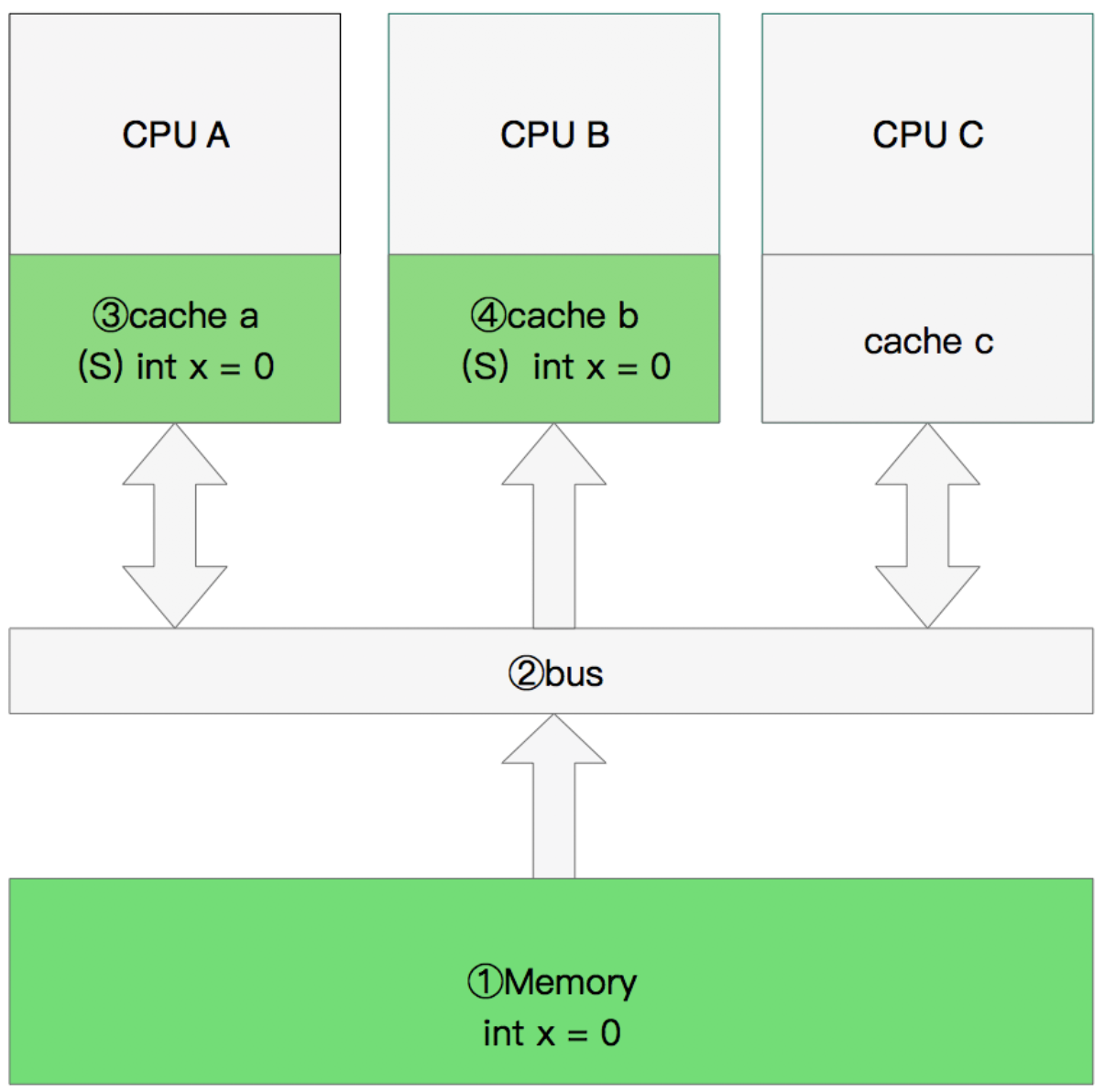
# 修改数据
- CPU A 计算完成后发指令需要修改x
- CPU A 将x设置为M状态(修改)并通知缓存了x的CPU B, CPU B将本地cache b中的x设置为I状态(无效)
- CPU A 对x进行赋值。
# 同步数据
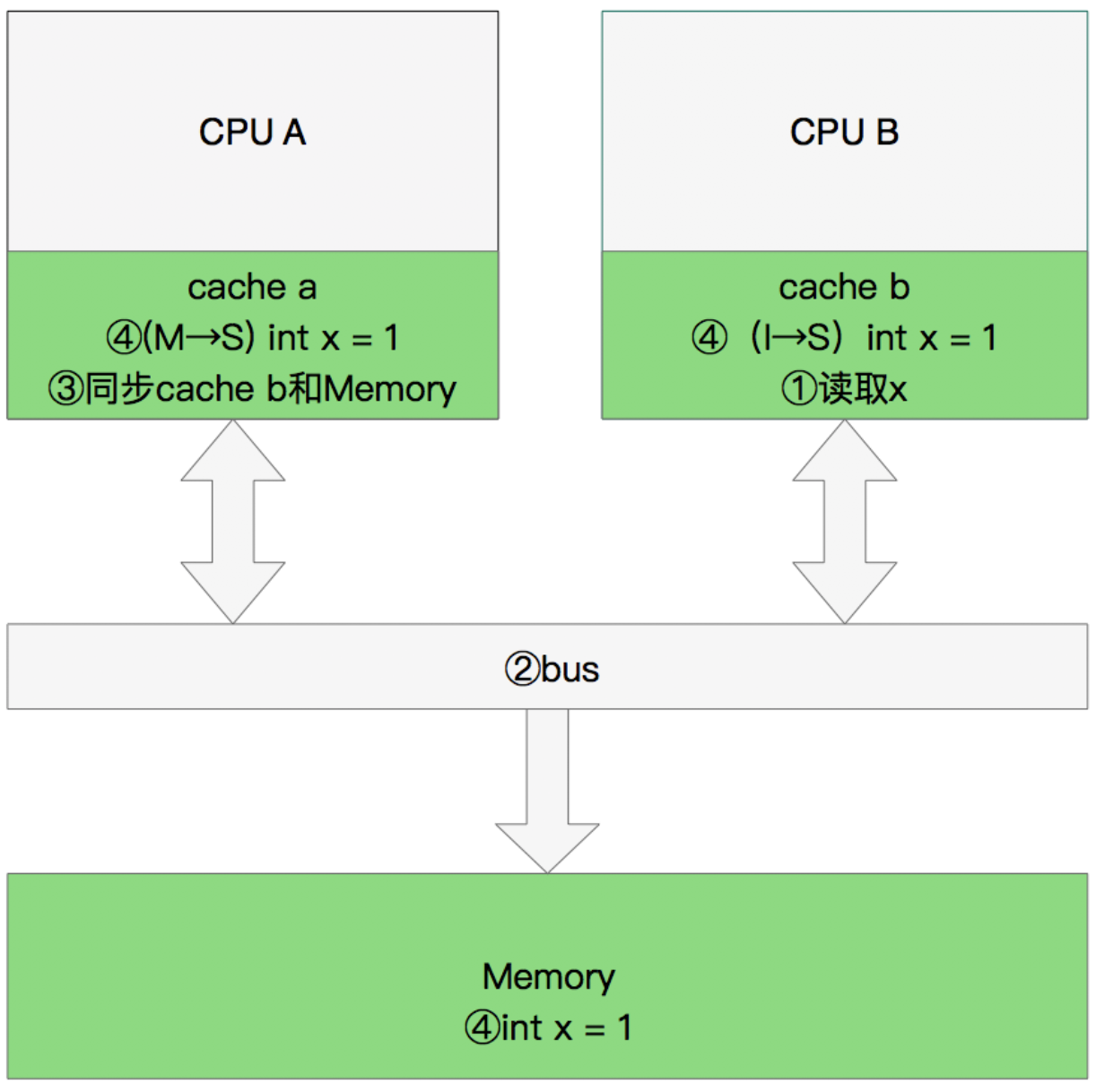
- CPU B 发出了要读取x的指令。
- CPU B 通知CPU A,CPU A将修改后的数据同步到主内存时cache a 修改为E(独享)
- CPU A同步CPU B的x,将cache a和同步后cache b中的x设置为S状态(共享)。
# 超过单个缓存行大小(64Bytes)怎么办?
此时MESI协议不适用,升级为总线锁方案,此时只有抢占到总线资源的CPU能访问主内存信息
# 缓存行伪共享
在多核 CPU 中,缓存系统以 缓存行(Cache Line) 为单位进行读写。当前主流 CPU 的缓存行大小通常是 64 字节。
在多线程环境下,如果多个线程“看似访问不同变量”,但这些变量刚好落在同一个缓存行中,就会产生无形的性能争用,这种现象就叫做 伪共享(False Sharing)。
虽然变量没有真正共享,但硬件角度认为它们在同一缓存块内,任意一个线程修改这个块,都会让其他线程的缓存失效,从而造成性能大幅下降。
# 🎯 为什么会出现伪共享?
可以这样理解:
- CPU 缓存以 缓存行(64B) 为基本单位
- A 线程修改了缓存行中的变量 a
- B 线程在访问同一个缓存行中的变量 b
虽然 a 与 b 是两个完全不同的变量,但它们挤在同一缓存行里,因此当:
- 线程 A 写 a → 会让 B 线程缓存的整个缓存行失效
- 线程 B 下次访问 b → 必须重新从 L3 或主存加载最新缓存行
如果两个线程频繁读写,就会不断重复 “失效 → 加载 → 再失效” 的过程,形成所谓的:
Cache Line 乒乓(Cache Line Ping-Pong)
这就是伪共享的本质。
# 🧪 示例说明
假设有两个 long 类型变量 a、b:
long a;
long b;
2
现在:
- 线程 T1 频繁写变量
a - 线程 T2 频繁写变量
b - 并且 a 与 b 在内存中紧挨着,落在同一个缓存行中
此时:
- T1 写 a → 使 T2 的缓存行无效
- T2 下一次写 b → 会让 T1 的缓存行无效
于是两个线程不断互相让对方“缓存失效”,导致性能急剧下降。
# 🛠 如何解决伪共享?
Java 8 提供了一个用来专门解决伪共享问题的注解:
# @sun.misc.Contended
只要在字段或类上加上 @Contended,JVM 就会自动为它们“填充空间”,使其独立占据不同的缓存行,避免多个线程在同一行发生争用。
示例:
@sun.misc.Contended
public volatile long value;
2
# ⚠️ 注意:该注解默认是不生效的,需要在 JVM 启动参数中加入:
-XX:-RestrictContended
加上这个参数后,只要标记了 @Contended 的字段,就会自动填充缓存行,从根本上避免伪共享带来的性能问题。
# ✅ 小结
- CPU 以 缓存行(64B) 为单位管理数据
- 多线程如果“碰巧”写同一个缓存行的不同变量,会触发伪共享
- 本质是 缓存行失效 + MESI 一致性协议造成的高成本同步
- Java 可以通过
@Contended或手动填充(padding)来解决
伪共享是高并发系统中典型的隐藏性能杀手,尤其在计数器、环形队列、统计指标等场景中更容易出现。理解并规避伪共享,可以显著提升应用性能。
# MESI优化和他们引入的问题
# CPU切换状态阻塞解决—存储缓存(Store Bufferes)
# Store Bufferes
- 为了避免这种CPU运算能力的浪费,Store Bufferes被引入使用。处理器把它想要写入到主存的值写到缓 存,然后继续去处理其他事情。当所有失效确认(Invalidate Acknowledge)都接收到时(其他所有的cpu都接收到消息后),数据才会最 终被提交。
# 硬件内存模型
- 对于所有的收到的Invalidate请求,Invalidate Acknowlege消息必须立刻发送 Invalidate并不真正执行,而是被放在一个特殊的队列中,在方便的时候才会去执行。 处理器不会发送任何消息给所处理的缓存条目,直到它处理Invalidate