
 Mysql索引底层数据结构与算法
Mysql索引底层数据结构与算法
# 索引的本质
索引是帮助MySQL高效获取数据的排好序的数据结构
索引数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree(B树)
# B-Tree结构
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排序
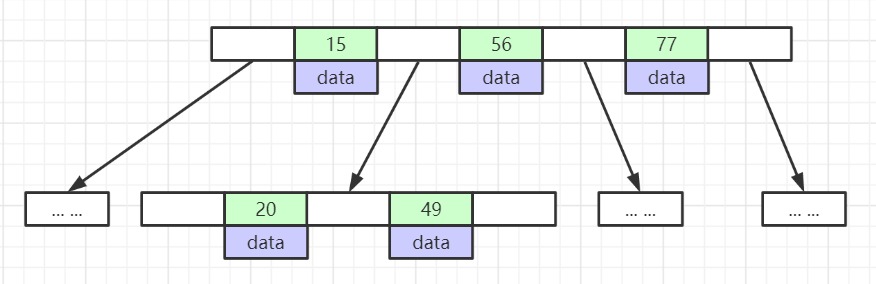
- 要点:多路平衡查找树,节点内有多个key与指针;查找最多访问树高 h 次磁盘页。
- 优点:把一个“节点=一页”装入内存,典型出度 d 很大(>100),相对二叉/红黑树而言树高很低(常≤3)要是和 B+Tree 比,B-Tree 会稍高一些,磁盘 I/O 次数小,适合做外存索引。
- 缺点:内节点既存 key 也存 data,单位页能容纳的关键字个数比 B+Tree 少,区间扫描不如带顺序指针的 B+Tree 友好。
# B+Tree结构
- B+Tree(B-Tree变种)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
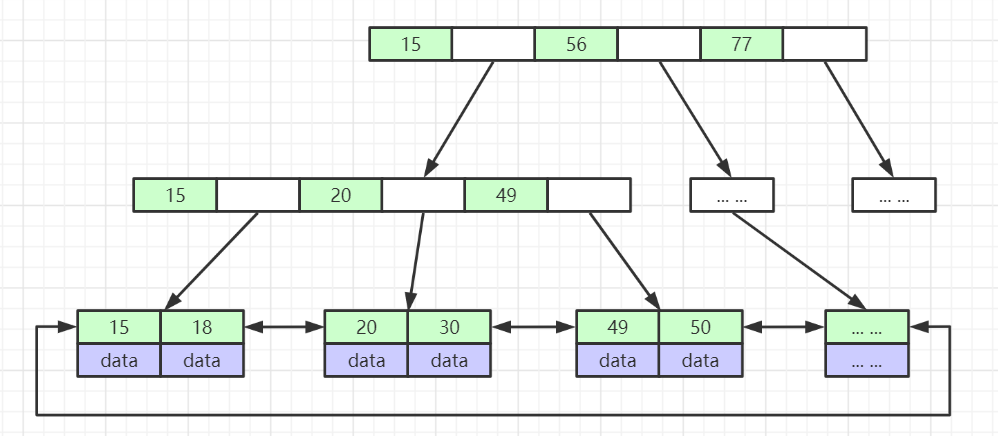
# 要点:内节点只存 key,不存 data;叶子节点存全部 key;常见实现会让叶子两两串起来做顺序访问。
一个索引页 = 一个节点 =(默认)16KB(
innodb_page_size可配置,但实例级固定)。页里有很多“项(entries)”**:
内页的项 =
分隔键(目录键) + 子页指针,注意子指针数 = 项数 + 1。叶页的项:
- 聚簇索引:
主键值 + 行记录(整行;超大列会放到溢出页,这里留指针/前缀)。 - 二级索引:
二级键 + 主键值(查整行需要“回表”到聚簇索引)。
- 聚簇索引:
# 16KB放不下怎么办?
页满→页分裂:新建兄弟页、把一半记录搬过去、父页插入新分隔键;必要时一路向上分裂,根分裂树高+1。
行很“胖”(TEXT/BLOB/超长VARCHAR)→大块内容放到溢出页,叶页只留短指针/前缀。
# 页分裂到底“向下”还是“横向”?
- 分裂本身是横向的:当某个页满了,会在同一层新建一个兄弟页,把大约一半记录搬过去;这叫页分裂(leaf split 或 internal split)。
- 向上的是“分裂结果的传播”:分裂后需要在父页插入一条新的分隔键与子指针;如果父页也满了,它也会横向分裂,再把“需要插入父亲”的动作继续往上传播。
- 只有根页分裂时树高才 +1:根横向分裂后,会新建一个新的根作为它们的父亲,于是高度增加一层。
# 数据量
假设 16KB 页,内页一条目录项(分隔键+指针)算 ~24B,可放约 600 项(内页一条目录项(分隔键K+子指针P)≈24B,16KB 页可容纳≈600 条目录项。注意严格来说子指针数=目录项数+1,用“≈600”做量级估算足够了);
叶页每条记录平均 ~100B,可放约 140 行;
高度=3(根/内/叶) 时:可挂叶页 ≈ 600² ≈ 36 万页 → 记录 ≈ 36 万 × 140 ≈ 5000 万行;
高度=4 时:记录量级可到 300 亿。 这就是为什么现实里 B+Tree 高度一般 2–4 层就够用的原因。
[ Root ] <-- 1 页 / | \ (600个子指针) ... (按内页中一个项24B算 共最多≈600个内页) [ Internal#1 ] [ Internal#2 ] ... [ Internal#600 ] <-- 每个内页≈600个子指针 / | \ (→ 600 个叶页) ... [ Leaf ] [ Leaf ] ... (最多≈600个) <-- 每个叶页≈140行 ├─[ pk:row ] | [ pk:row ] | ... (≈140项) ||| → 下个叶页1
2
3
4
5
6
7
8
9
10
11# 为啥是 600² ?
以**高度=3(根/内/叶)**为例:
- Root 页:有≈600 个子指针 → 指向≈600 个二层内页。
- 每个二层内页:又各自有≈600 个子指针 → 各自指向≈600 个叶页。
- 所以叶页总数 ≈ 600 × 600 = 600² = 360,000 页。
每个叶页能装≈140 行(假设每行≈100B),因此: 总行数 ≈ 360,000 × 140 ≈ 50,400,000(约 5,000 万)。
# 优点:
- 内节点更“瘦”,出度更大→树更矮→更少 I/O,更适合外存。
- 叶子链表使范围/排序扫描很高效。
# 缺点:叶子集中数据,随机点查仍是“走到叶子”一跳,但这也是它以顺序/范围查询友好换来的典型取舍。
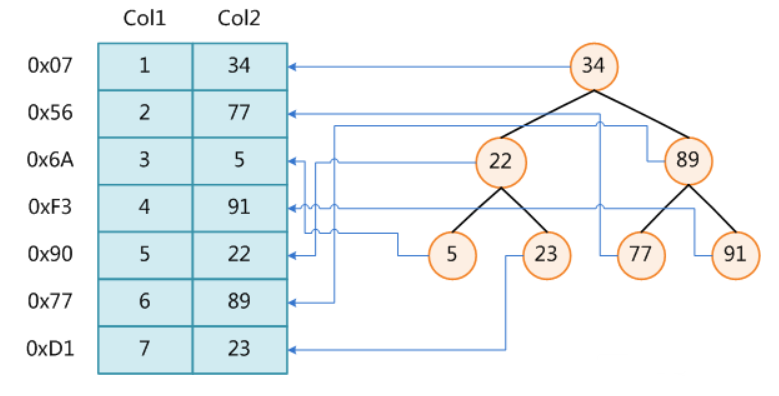
# hash结构
- Hash
- 对索引的key进行一次hash计算就可以定位出数据存储的位置
- 很多时候hash索引要比B+树更高效
- 仅能满足 “=” ,“IN” ,不支持范围查询
- hash冲突问题
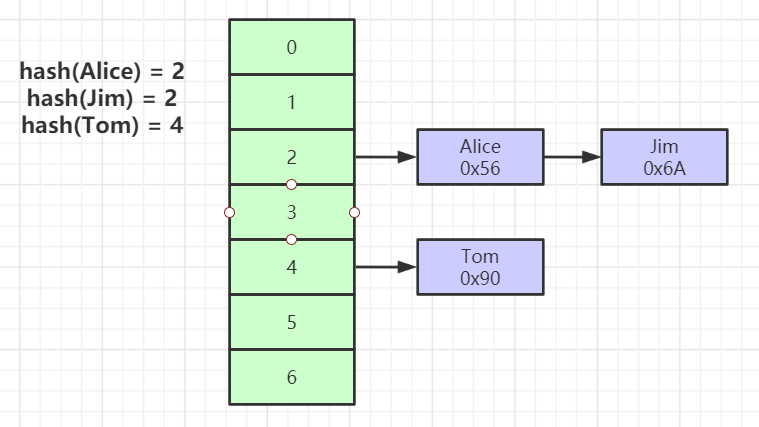
要点:对 key 做一次 hash 即可定位;MySQL 中常见于 MEMORY 引擎或某些场景。
优点:等值匹配(=、IN)非常快,很多时候比 B+Tree 等值还快。
缺点:
- 不支持范围查询、排序、前缀匹配等。
- 存在哈希冲突,需要额外开销处理。
# MyISAM存储引擎索引实现
- MyISAM索引文件和数据文件是分离的(非聚集)
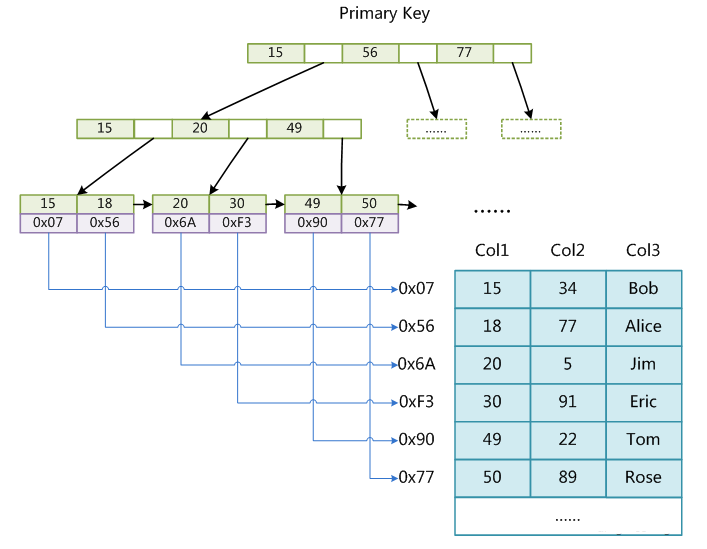
要点:索引文件与数据文件分离;索引叶子结点的 data 域存**“物理地址”**。主/辅索引结构一样(主键要求唯一)。
优点:
- 索引结构简单;不依赖主键值回表,直接根据地址取行。
缺点:
- “非聚集”带来随机 I/O更多;与 InnoDB 相比,更新/碎片后可能更易退化。
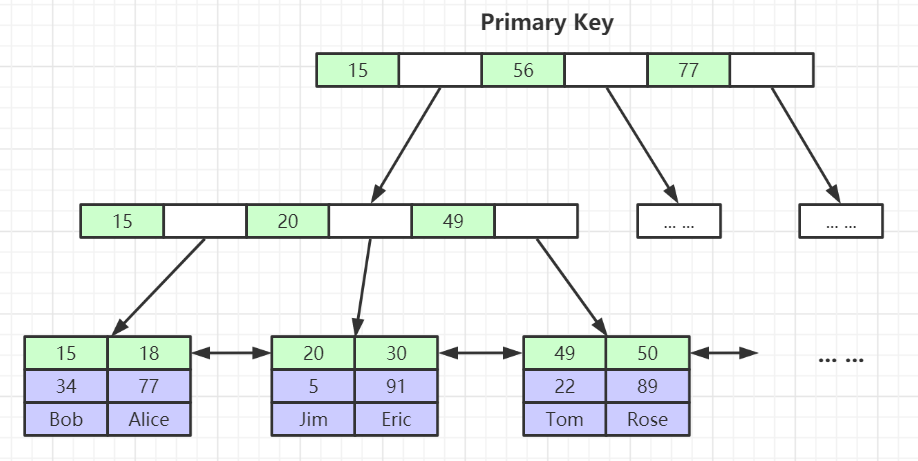
# InnoDB存储引擎索引实现
InnoDB索引实现(聚集)
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶子节点包含了完整的数据记录
- 为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?(提高效率,如果没有建主键,MySQL会自动加上一列隐式ROWID,而且自增主键在构建B+Tree树的时候效率更高,因为本身自增主键就是有序的)
- 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
# 主键索引
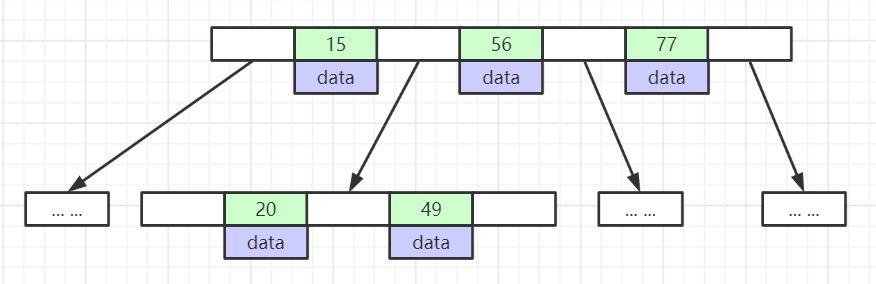
# 二级索引(非主键索引)
# 联合索引
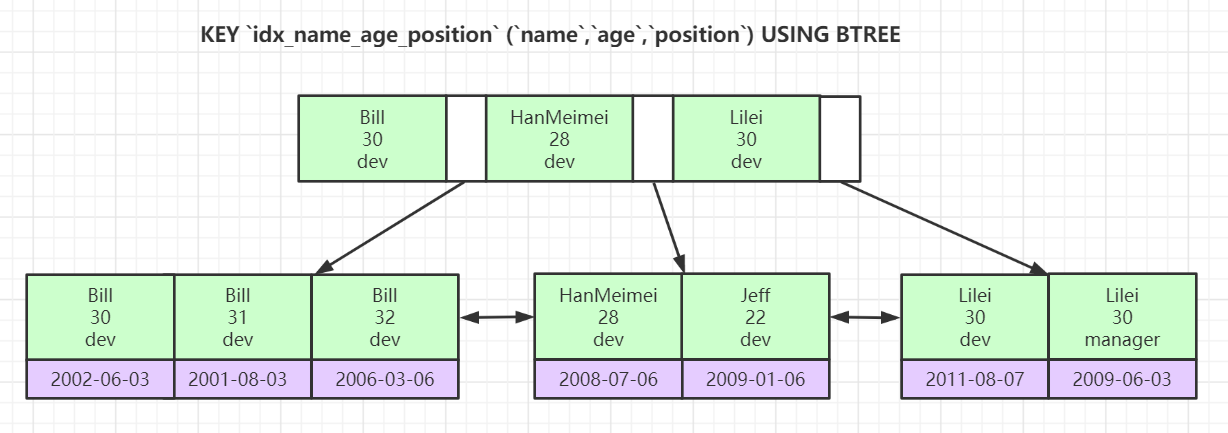
联合索引遵循索引最左前缀原理
要点:
- 数据文件本身就是一棵 B+Tree:主索引(聚簇索引)叶子=整行数据。
- **二级(辅助)索引的叶子存“主键值”**而非物理地址,二次查主键才能取到整行(“回表”)。
优点:
- 按主键范围/顺序访问很高效;物理组织天然有序。
- 统一以主键为“行标识”,二级索引更一致、节省存储(相对存地址可能更稳定)。
缺点与选型提示:
- 二级索引查整行需二次检索(回表)。
- 主键过长会让所有二级索引变“胖”(因为叶子存主键),影响空间与缓存效率;非单调主键插入触发 B+Tree 频繁分裂,写入性能差,自增主键更合适。
# 为什么不是二叉/红黑树?
- 做外存索引最关键是把磁盘 I/O 次数降到很小;B-/+Tree 能以极小的树高达到这个目标,而红黑树等高度更深、局部性差,在磁盘上 I/O 代价明显更高,所以数据库/文件系统普遍选择 B-/+Tree。